心血来潮写的Wordle提示器,思路大概如下
- 把谜题中已经暴露的信息转换为正则表达式
- 绿色=固定字母,黄色=含有字母&位置错误,黑色=不含字母
- 从词表(*)里筛选出符合规范的词,即所有的“可能答案”
- 计算所有可能答案的mutual information,找到之中mutual information最大的(几个)词(**)
- 这里使用了简单的计数法:绿色=2分,黄色=1分,黑色=0分
注:
词表:我用了github上的这个词表derekchuank/high-frequency-vocabulary。经嘟友@[email protected] 提醒,其实wordle有dump出的词表,词库大约2.3k,允许输入大约10.6k,来源自这个reddit讨论串 a_note_on_wordles_word_list/。可以自行替换。
答案表:reddit的讨论指出每期问题的答案是人工挑选的而非随机抽取,这意味着信息分布与默认的平均分布不符。Well,既然答案表有2.3k词,就算是人工挑选也足够多词了。
有趣的发现:
- 从词表上来看,最好的“起始词”并不是adieu而是rates, aries, cares, lanes这几个,因为u这个原因出现次数其实不如辅音r和s高
- 就算用词表作弊,也挺需要运气的,比如Wordle 243,最后需要从4个合法词里随机尝试,我的这个策略的步数期望值是4.
代码大概这样
import numpy as np
import re
# # create 5-letter word list
# with open("30k.txt") as file:
# for line in file:
# w = line.rstrip()
# if len(w)==5:
# with open('5letterwords.txt', 'a') as fnew:
# fnew.write(w+'\n')
def info_score(target,current,matchscore=2,containscore=1):
"""
compute information score
target: target word
current: current try
change the scores to optimize the searching process
"""
s = 0
for i in range(5):
if current[i]==target[i]:
s+=matchscore
elif current[i] in target:
s+=containscore
return s
def main():
# run hinter
# get word list
with open("5letterwords.txt") as f:
words=[line.strip() for line in f]
# initialize masks
letters_contain = []
pattern = ["[^0]"]*5
done = [False]*5
while not all(done):
# new inpt from user
w = input("Please enter your first try word: ")
m = input("Please enter your result (black=0,yellow=1,green=2): ")
# loop through new input
for i in range(5):
if m[i]=='2':
# correct, remove regax mask and mark as done
pattern[i]=w[i]
done[i]=True
elif m[i]=='1':
# semi-correct, add to contain list and mask this index
letters_contain+=w[i]
pattern[i]=pattern[i][:-1]+w[i]+']'
elif m[i]=='0':
# wrong guess, add to all regax mask
for j in range(5):
if not done[j]:
pattern[j]=pattern[j][:-1]+w[i]+']'
# exit if done
if all(done):
print("You solved it. Bye.")
exit()
# apply regax and contain list
words_new = [wd for wd in words if
re.match('^'+("").join(pattern)+'$',wd)
is not None and all([l in wd for l in letters_contain])]
# exit if funny problem happened
if not words_new:
print("out of words, maybe something wrong?")
exit()
# compute similarity matrix
sim_matrix =[[info_score(x,y) for y in words_new] for x in words_new]
# zip and sort and print results
mutural_info_sums = list(zip(words_new, [sum(x) for x in sim_matrix]))
best_guess = [x[0] for x in sorted(mutural_info_sums, key=lambda x: x[1],
reverse=True)[:5]]
print("Best next guesses are "+(", ").join(best_guess)+".")
if __name__ == "__main__":
main()
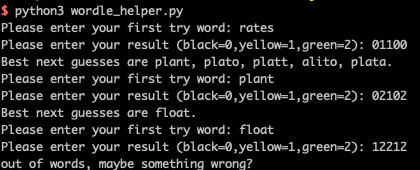
效果大概是这样
答案是robin
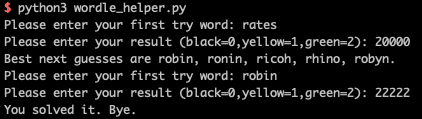
答案是slime:
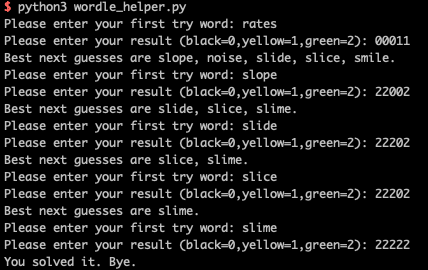
答案是abbey:
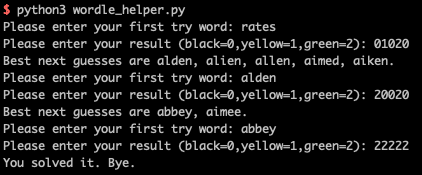
答案是aloft: 很奇怪这个词不在30k list里